强交互数据分析编程 esproc spl-九游会登陆

数据分析编程?
看起来简单,其实很难
例简单查询
select id, name from t where id = 1
select area,sum(amount) from t group by area

例每支股票最长连续上涨天数
select code, max(con_rise) as longest_up_days
from (
select code, count(*) as con_rise
from (
select code, dt,
sum(updown_flag) over (partition by code order by code, dt) as no_up_days
from (
select code, dt,
case when cl > lag(cl) over (partition by code order by code, dt) then 0
else 1 end as updown_flag
from stock
)
)
group by code, no_up_days
)
group by code
例1分钟内连续得分3次的球员
例每7天中连续三天活跃的用户数
例每天新用户的次日留存
例股价高于前后5天时当天的涨幅
例...

调试很麻烦
sql没有设置断点、单步执行这些很常见的调试方法,嵌套多层时就要逐层拆分执行。
select code, max(con_rise) as longest_up_days
from (
select code, count(*) as con_rise
from (
select code, dt,
sum(updown_flag) over (partition by code order by code, dt) as no_up_days
from (
select code, dt,
case when cl > lag(cl) over (partition by code order by code, dt) then 0
else 1 end as updown_flag
from stock
)
)
group by code, no_up_days
)
group by code
封闭沉重,环境复杂,外部数据要先入库,琐事多


6大优势助力数据分析师
1更简洁的代码
例每支股票最长连续上涨天数
spl显得更简单,不再需要循环语句
sql
select code, max(con_rise) as longest_up_days
from (
select code, count(*) as con_rise
from (
select code, dt,
sum(updown_flag) over (partition by code order by code, dt) as no_up_days
from (
select code, dt,
case when cl > lag(cl) over (partition by code order by code, dt) then 0
else 1 end as updown_flag
from stock
)
)
group by code, no_up_days
)
group by code
spl
| a | |
| 1 | =stock.sort(stockrecords.txt) |
| 2 | =t(a1).sort(dt) |
| 3 | =a2.group(code;~.group@i(cl< cl[-1]).max(~.len()):max_increase_days) |
python
import pandas as pd
stock_file = "stockrecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['code','dt'],inplace=true)
stock_group = stock_info.groupby(by='code')
stock_info['label'] = stock_info.groupby('code')['cl'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('code'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.dataframe(list(max_increase_days.items()), columns=['code', 'max_increase_days'])
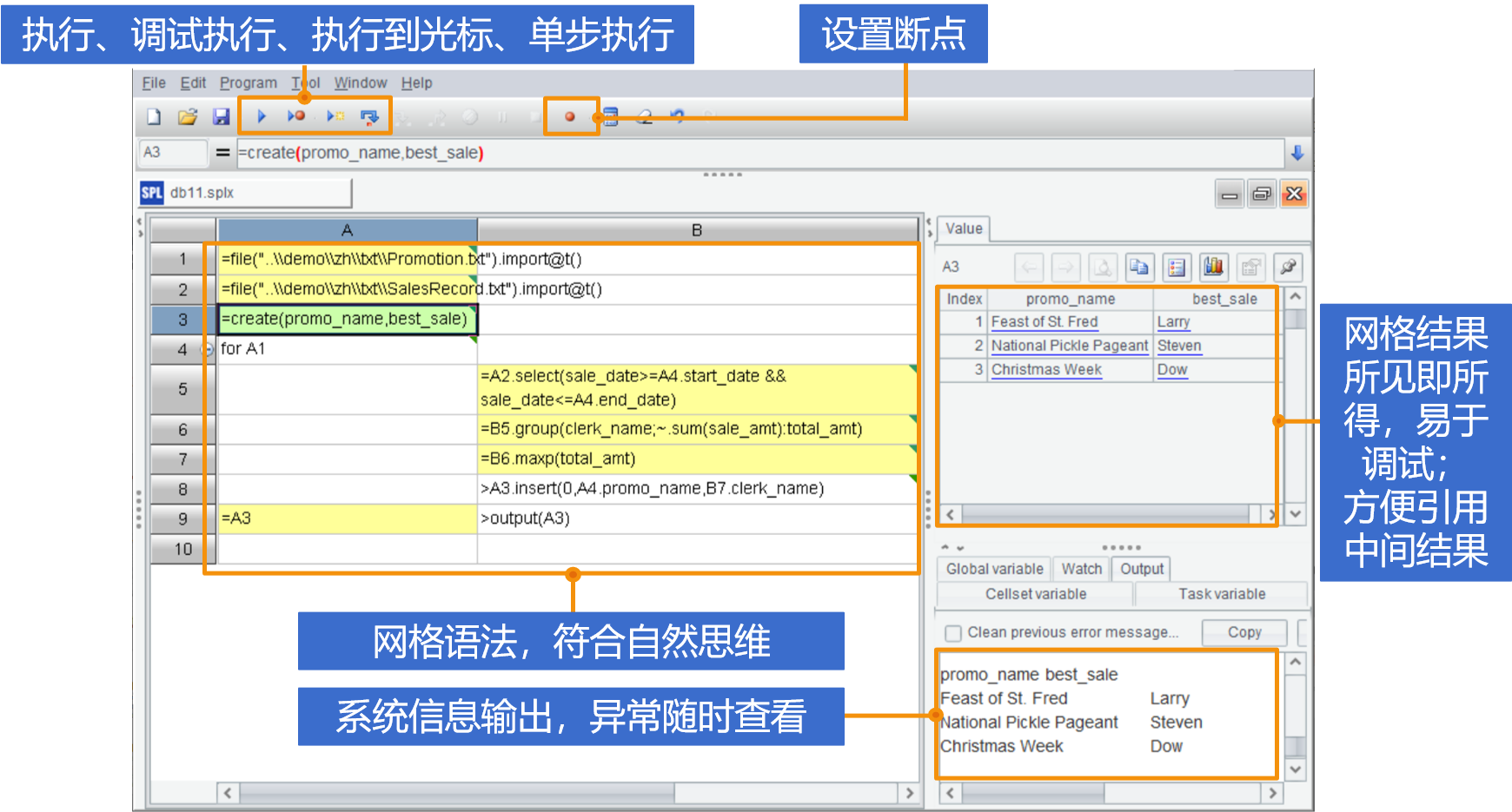
2强交互探索分析,便捷调试
例找出股票连涨超过5天的区间

3内置并行外存运算,跑出高性能
内存计算
| a | |
| 1 | smalldata.txt |
| 2 | =file(a1).import@t() |
| 3 | =a2.groups(state;sum(amount):amount) |
外存计算
| a | |
| 1 | bigdata.txt |
| 2 | =file(a1).cursor@t() |
| 3 | =a2.groups(state;sum(amount):amount) |
串行
| a | |
| 1 | bigdata.txt |
| 2 | =file(a1).cursor@t() |
| 3 | =a2.groups(state;sum(amount):amount) |
并行
| a | |
| 1 | bigdata.txt |
| 2 | =file(a1).cursor@tm() |
| 3 | =a2.groups(state;sum(amount):amount) |
4轻量便捷
普通笔记本即可流畅运行,无须服务器集群
高压缩率文件存储数据,易于携带

5开放体系,多样数据源直接算


6纯java,探索结果直接进企业应用

比sql好点,复杂情况还是麻烦
例每支股票最长连续上涨天数
import pandas as pd
stock_file = "stockrecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['code','dt'],inplace=true)
stock_group = stock_info.groupby(by='code')
stock_info['label'] = stock_info.groupby('code')['cl'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('code'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.dataframe(list(max_increase_days.items()), columns=['code', 'max_increase_days'])
调试还是print大法

没大数据支持,伪并行

非java体系,探索结果进企业应用经常还要重写
