sql作为常使用的结构化数据处理语言存在如下问题
难写难调试
sql不提倡过程,难以实现复杂计算,经常要写得很长,难写难调试
过于封闭
sql强依赖数据库,无法计算文件等库外数据,很难跨库计算
*扩展阅读:

结构化数据计算一直是数据处理的主流
分析处理结构化数据的三种方式
sql作为常使用的结构化数据处理语言存在如下问题
sql不提倡过程,难以实现复杂计算,经常要写得很长,难写难调试
sql强依赖数据库,无法计算文件等库外数据,很难跨库计算
*扩展阅读:
select max(continuousdays)-1 from (select count(*) continuousdays from (select sum(changesign) over(order by tradedate) unrisedays from (select tradedate, case when closeprice>lag(closeprice) over(order by tradedate) then 0 else 1 end changesign from stock) ) group by unrisedays)
sql在使用窗口函数的情况下嵌套三层完成;
前面读懂了吗?
| a | |
|---|---|
| 1 | =stock.sort(tradedate) |
| 2 | =0 |
| 3 | =a1.max(a2=if(closeprice>closeprice[-1],a2 1,0)) |
其实这个计算很简单,按照自然思维:先按交易日排序(行1),然后比较当天收盘价比前一天高就 1,否则就清零,最后求个最大值(行3)
python相对sql更加灵活开放,但仍存在如下问题
pandas不是专业结构化数据计算包,在处理分组有序等复杂运算时较为繁琐
pandas等计算包只有专业程序员才能玩得转
*扩展阅读:
import time
import numpy as np
import pandas as pd
s = time.time()
sales = pd.read_csv("c:\\users\\sean\\desktop\\kaggle_data\\music_project_data\\sales.csv",sep='\t')
sales['orderdate']=pd.to_datetime(sales['orderdate'])
sales['y']=sales['orderdate'].dt.year
sales['m']=sales['orderdate'].dt.month
sales_g = sales[['y','m','amount']].groupby(by=['y','m'],as_index=false)
amount_df = sales_g.sum().sort_values(['m','y'])
yoy = np.zeros(amount_df.values.shape[0])
yoy=(amount_df['amount']-amount_df['amount'].shift(1))/amount_df['amount'].shift(1)
yoy[amount_df['m'].shift(1)!=amount_df['m']]=np.nan
amount_df['yoy']=yoy
print(amount_df)
e = time.time()
print(e-s)
python通过多步算出结果,实现起来比sql更容易
但python代码比较繁琐,写出来并不容易
| a | |
|---|---|
| 1 | =file("c:\\sales.csv").import@t() |
| 2 | =a1.groups(year(orderdate):y,month(orderdate):m,sum(amount):x) |
| 3 | =a2.sort(m) |
| 4 | =a3.derive(if(m==m[-1],x/x[-1]-1,null):yoy) |
spl的分步代码更为简洁,实现更为简单
一些场景下还会使用java、vba实施结构化数据计算

java和vba都不是为结构化数据计算设计的,缺少集合化计算类库,编码过于复杂

spl特别适合复杂过程运算
专门针对结构化数据表设计,类库丰富,远超sql和python

结构化数据总是批量形式
集合成员可游离在集合外存在,方便单独引用;独立运算或及其它游离成员再组合新集合运算
允许游离成员组成新集合
运算不仅与数据本身有关,还和数据所在位置有关
| a | |
|---|---|
| 1 | =人员表.group(生日).select(~.count(1)>1).conj() |
| a | |
|---|---|
| 1 | =v.len() |
| 2 | =v.to(a1\4 1,a1*3\4).run(value-=v(a1\2).value) |
| a | b | |
|---|---|---|
| 1 | ... | |
| 2 | =a1.select(height>=1.7) | =a1.select(sex=="female") |
| 3 | =a2^b2 | =a1.select(height>=1.7&&sex=="female") |
| 4 | =a2\b2 | =a1.select(height>=1.7&&sex!="female") |
| a | b | |
|---|---|---|
| 1 | ... | ... |
| 2 | =a1.select(sex=="male") | =a1.select(sex=="female") |
| 3 | =a2.conj(b2.([a2.~,~])) | =a3.minp@a(abs(~(1).height-~(2).height)) |
| a | |
|---|---|
| 1 | ... |
| 2 | =a1.group((# 2)\3) |
| 3 | =a1.group(#%3 1) |
| a | |
|---|---|
| ... | ... |
| 3 | =a2.derive(price-price[-1]:gain) |
| 4 | =a2.derive(price[-1:1].avg():mavg) |
with tt as (select rank() over(partition by uid order by logtime desc) rk, t.* from 登录表 t) select uid,(select tt.logtime from tt where tt.uid=ttt.uid and tt.rk=1) -(selet tt.logtim from tt where tt.uid=ttt.uid and tt.rk=2) 间隔 from 登录表 ttt group by uid
聚合函数返回值不一定是单值,也可以返回一个集合
彻底的集合化后很容易针对分组子集实施返回集合的聚合运算
| a | ||
|---|---|---|
| 1 | =登录表.groups(uid;top(2,-logtime)) | 最后2个登录记录 |
| 2 | =a1.new(uid,#2(1).logtime-#2(2).logtime:间隔) | 计算间隔 |
with b as (select lag(销售额) over (order by 月份) f1, lead(销售额) over (order by 月份) f2, a.* from 销售表 a) select 月份,销售额, (nvl(f1,0) nvl(f2,0) 销售额)/(decode(f1,nulll,0,1) decode(f2,null,0,1) 1) 移动平均 from b
窗口函数只有简单的跨行引用,涉及集合要用成员去拼
有序集合上可提供跨行集合引用方案
| a | |
|---|---|
| 1 | =销售表.sort(月份).derive(销售额[-1,1].avg()):移动平均) |
select max(连续日数) from (select count(*) 连续日数 from (select sum(涨跌标志) over ( order by 交易日) 不涨日数 from (select 交易日, case when 收盘价>lag(收盘价) over( order by 交易日 then 0 else 1 end 涨跌标志 from 股票 )) group by 不涨日数)
另一种和次序有关的分组,条件成立时产生新组
| a | |
|---|---|
| 1 | =股票.sort(交易日).group@i(收盘价 < 收盘价[-1]).max(~.len()) |
with a as
(select 代码,交易日, 收盘价-lag(收盘价) over (paritition by 代码 order by 涨幅) from 股票)
b as
(select 代码,
case when 涨幅>0 and
lag(涨幅) over (partition by 代码 order by 交易日) >0 and
lag(涨幅,2) over partition by 代码 order by 交易日) >0
then 1 else 0 end 三天连涨标志 from a)
select distinct 代码 from b where 三天连涨标志=1
分组子集与有序计算的组合
| a | |
|---|---|
| 1 | =股票.sort(交易日).group(代码) |
| 2 | =a1.select((a=0,~.pselect(a=if(收盘价>收盘价[-1],a 1,0):3))>0).(代码) |
select avg(涨幅) from ( select 交易日, 收盘价-lag(收盘价) over ( order by 交易日) 涨幅 from 股价表 where 交易日 in (select 交易日 from (select 交易日, row_number() over(order by 收盘价 desc) 排名 from 股票) where 排名<=3 )
无序集合不能利用位置访问相邻成员,计算量增大
有序集合可以提供丰富的按位置访问机制
| a | |
|---|---|
| 1 | =股票.sort(交易日) |
| 2 | =a1.calc(a1.ptop(3,-收盘价),收盘价-收盘价[-1]).avg() |
过滤、计算列、位置引用、相邻引用、排序/排名、列上的宏运算
分组汇总/分组子集、枚举分组/序号分组、有序分组/条件分组、转置与扩展
集合交并差、归并、外键关联、同维主子关联
…
spl与excel配合可以增强excel计算能力,降低计算实施难度
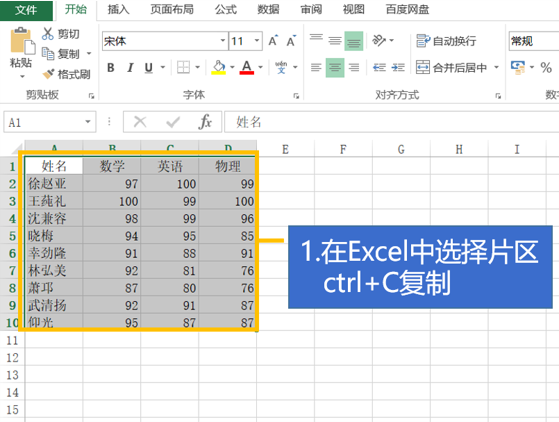
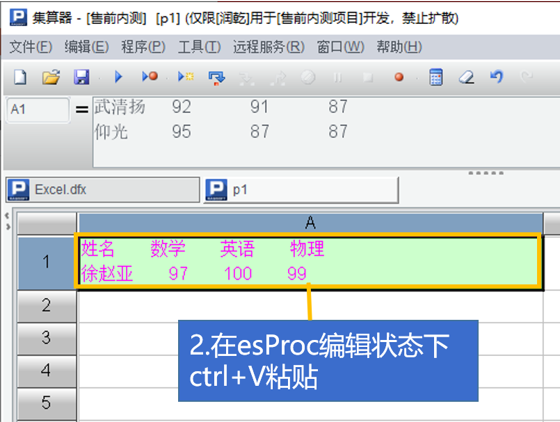
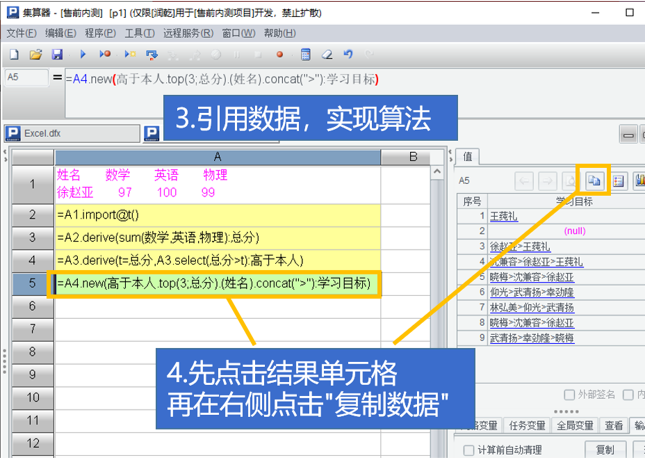
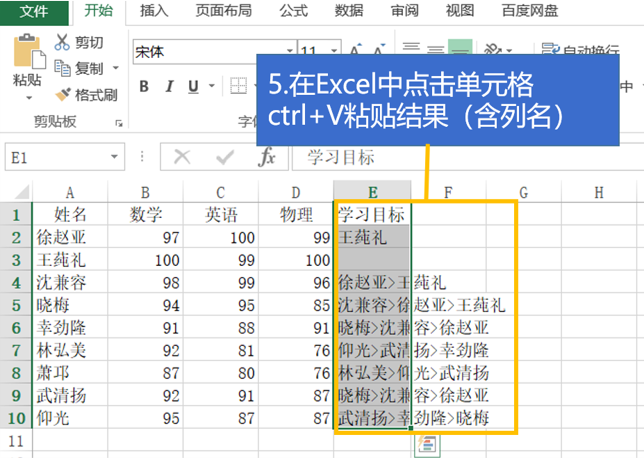
通过spl的excel插件可以在excel中使用spl函数进行计算,也可以在vba中调用spl脚本
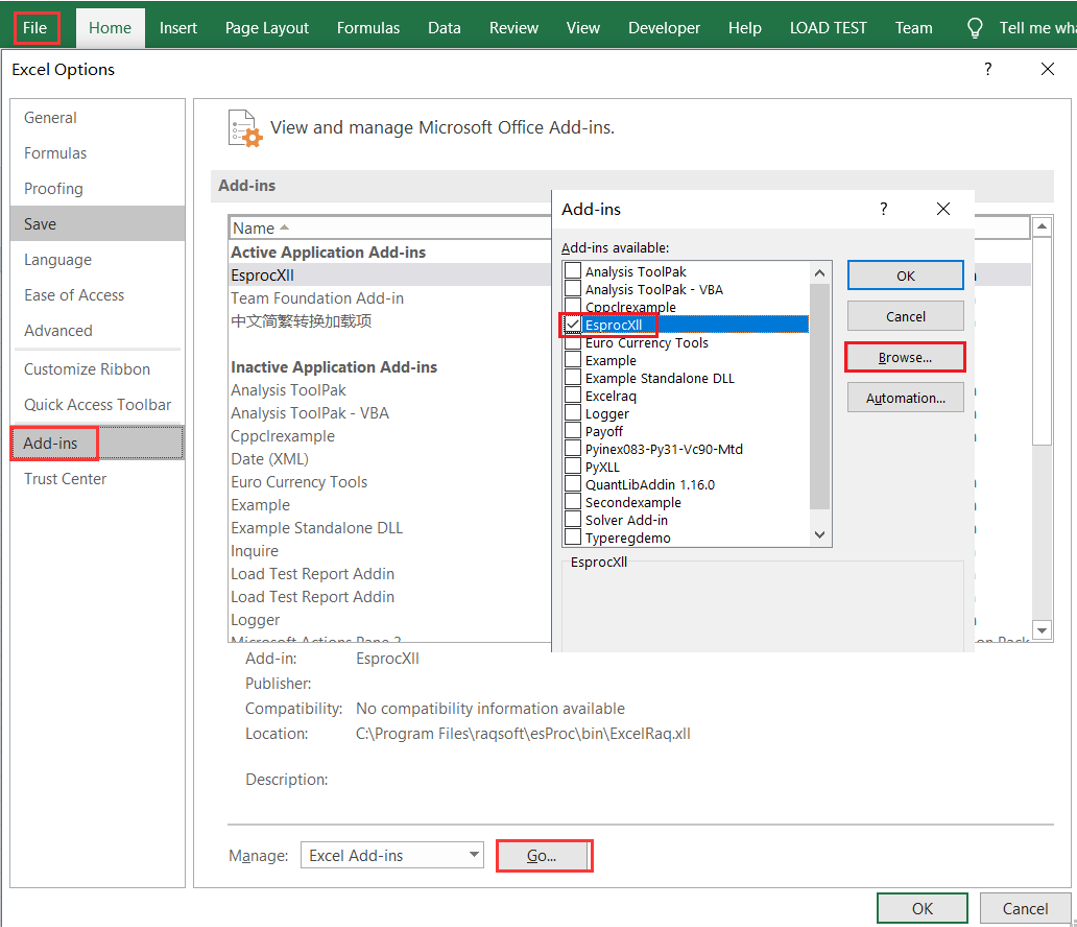


spl可以调用报表工具生成、输出报表
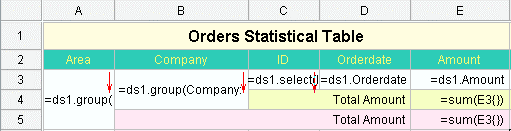
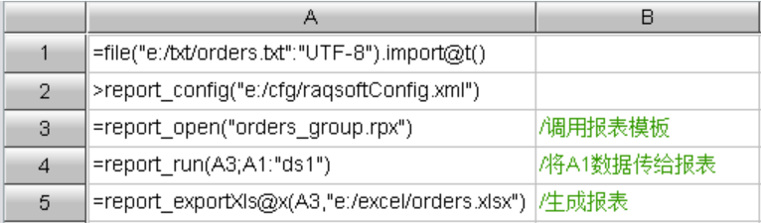
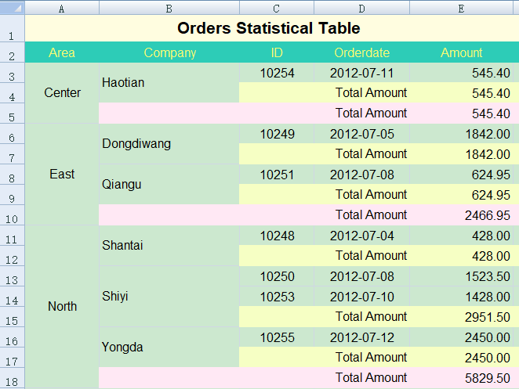
spl提供了外存游标、并行计算等机制实现大数据文件计算
python未提供大数据支持,需要手写代码,非常繁琐

| a | b | |
|---|---|---|
| 1 | =file(file_path).cursor@tc() | /创建大文件游标 |
| 2 | =a1.sortx(key) | /游标排序 |
| 3 | =file(out_file).export@tc(a2) | /结果流式输出到文件 |
通过spl可以针对文本、excel等文件使用sql进行查询;提供不依赖于数据库的sql查询能力
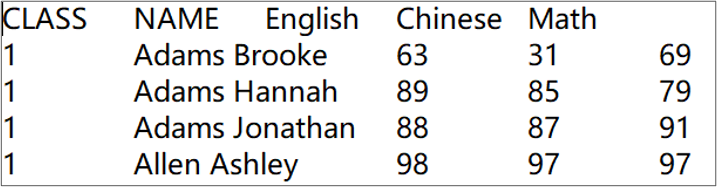
| a | |
|---|---|
| 1 | $select class,min(english),max(chinese),sum(math) from e:/txt/students_scores.txt group by class |
| a | |
|---|---|
| 1 | $select sum(s.quantity*p.price) as totalfrom e:/txt/sales.txt as s join e:/txt/products.txt as p on s.productid=p.id where s.quantity<=10 |