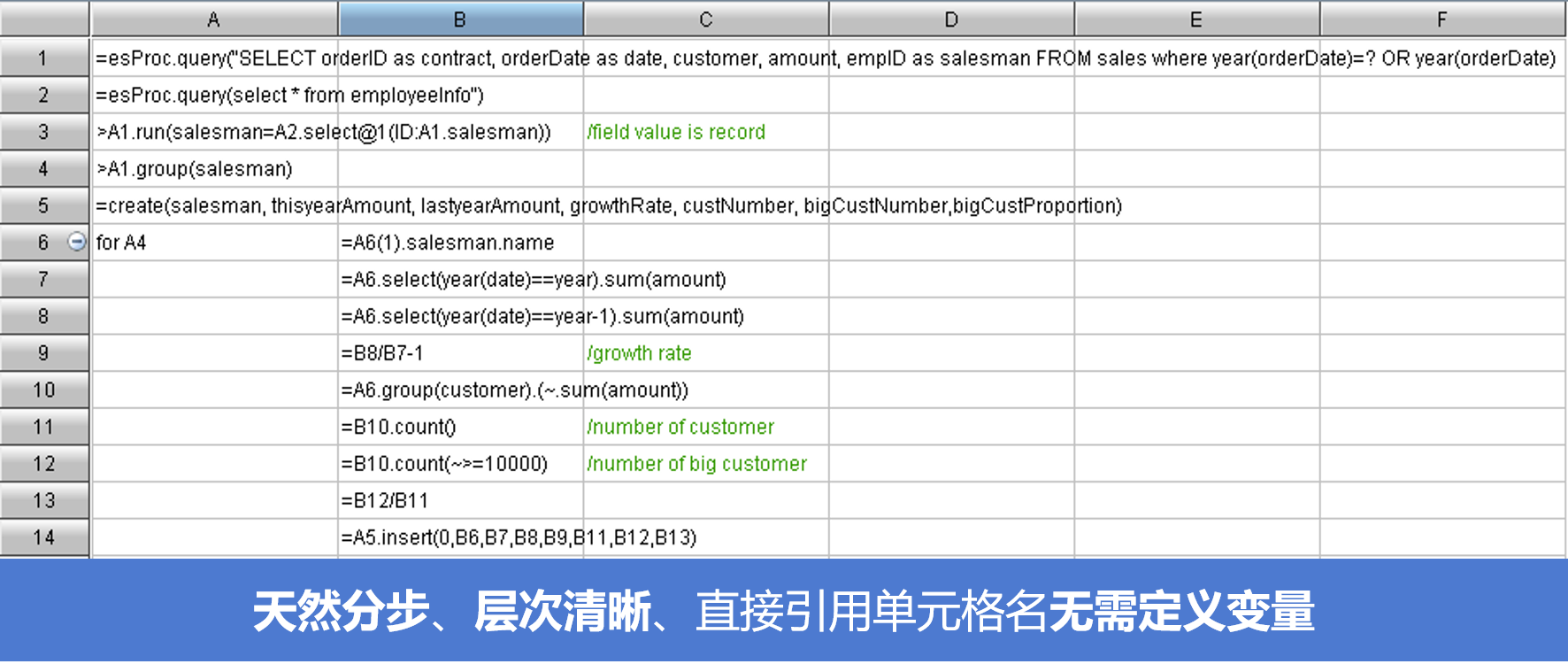
集算器 -九游会登陆
01qdbase是什么?
qdbase spl 是什么?
- 数据计算和处理引擎,可用作分析型数据库和中间件
- 结构化和半结构化数据计算处理
- 线下跑批、在线查询
- 既非sql体系,也非nosql技术
- 自创spl语法,简洁高效

qdbase spl 应对什么痛点?
面向线下跑批、在线查询等数据计算场景
- 时间窗口不够,半夜跑批跑不完,出错来不及重来;月末年头担惊受怕
- 出个报表十分钟,业务人员拍桌子;预计算难预测,业务人员不满意
- 在线用户多一点,时间跨度长一点,数据库就像死了一样
- n层嵌套长sql,存储过程几十k,过几天自己都看不懂
- db/nosql/文本/json/web几十种数据源,做梦都想跨源混合算
- 数据量大了冷热数据分库,再想全量(t 0)统计难死人
- 过度依赖存储过程,应用难移植,架构难调整
- 数据库里表太多,存储计算资源耗尽,想删不敢删
- 报表没完没了做不完,人员成本投入何时休
- ……

qdbase spl 对标什么?
采用sql语法的、应用于olap场景的数据库
- 常规数据库:mysql、postgresql、oracle、db2、…
- hadoop上的数据仓库:hive、spark sql、…
- 新型分布式数据仓库/mpp:…
- 云数据仓库:snowflake、…
- 数据库一体机:exadata、…
其它数据分析与统计技术
- python, scala, java, kotlin, …
qdbase spl
- 低代码
- 高性能
- 轻量级
- 全功能
qdbase spl 有什么相对sql的优势?
sql

spl

qdbase spl 有什么相对java的优势?
java
spl
qdbase spl 有什么相对python的优势?
python
spl
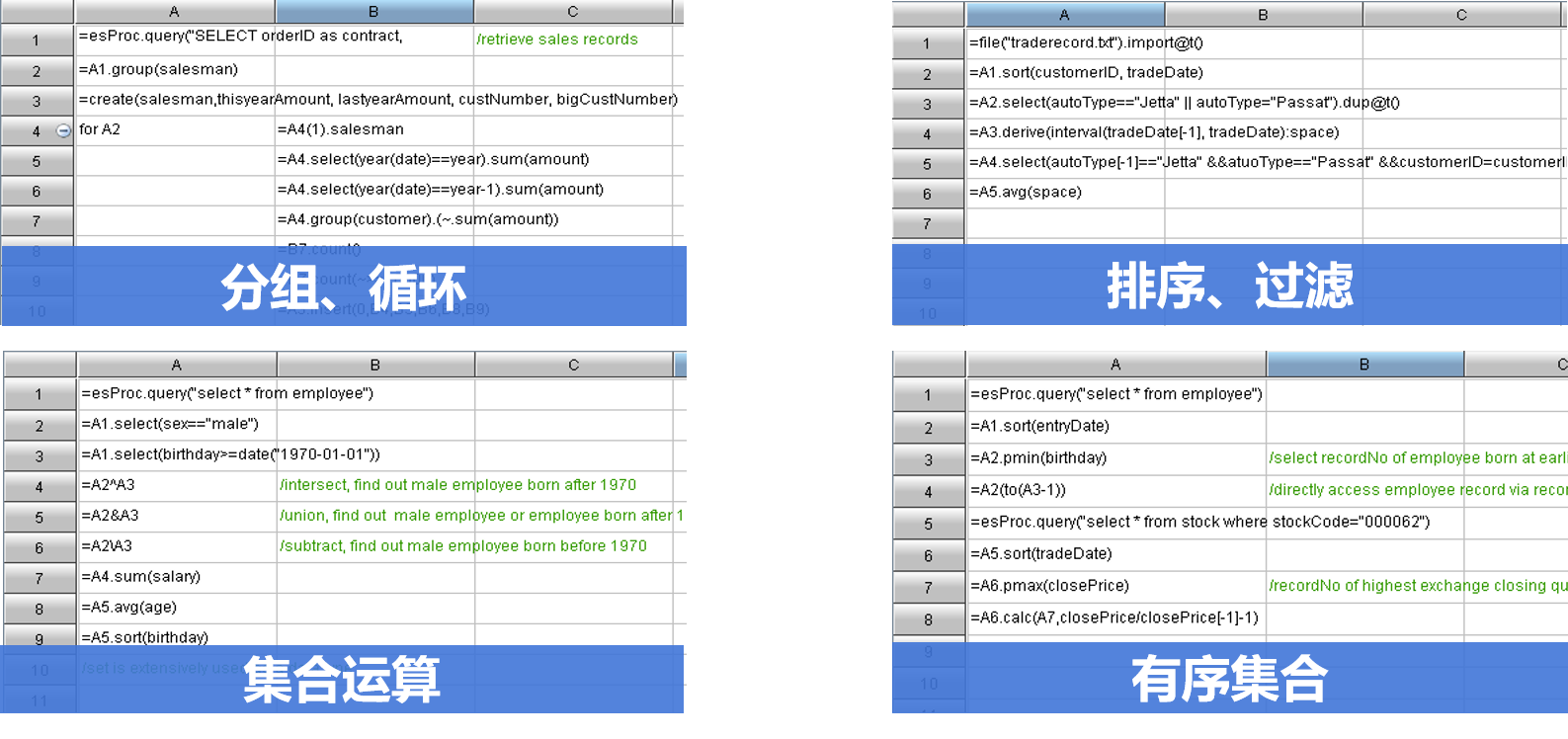
02案例简析
案例国家天文台星体聚类
- 11张照片,每张500万天体
- 天文规则(三角函数计算)聚类
- 平方级复杂度,500万*500万*10=250万亿次对比
- 50万天体测试
- python 200行,单线程 6.5天
- sql 100cpu集群 3.8小时
- 50万天体测试, 2.5分钟
- 500万天体, 3小时
- 代码 50行
案例某保险公司车险跑批
- 保单表 3500万行,明细表 1.23亿行
- 关联方式多样需要分别处理
- informix
- 10天新增保单关联 47分钟
- 30天新增保单关联 112分钟
- 代码 1800行
- 10天新增保单关联 13分钟
- 30天新增保单关联 17分钟
- 代码 500行
案例某银行对公贷款业务跑批
- 48个sql步骤,3300行
- 历史数据量1.1亿行,每日新增137万行
- 复杂多表关联
- 小型机aix db2
- 运算时间 1.5小时
- 用时 10分钟,代码 500行
案例手机银行多并发帐户查询
- 用户多,并发访问量大
- 机构信息经常变更,需要及时关联
- hadoop上商用数仓无法满足高并发要求
- 换用6台elasticsearch集群能应对并发,但不能实时关联,数据更新时间长,期间只能停止服务
- 单机做到es集群同样并发量
- 实时关联,机构信息更新零等待
案例某银行贷款去重户数指标统计
- 标签众多,数百个标签任意组合查询
- 2000万行大表及更大的明细表关联、过滤、汇总计算
- 每个页面涉及近200指标计算,10并发共2000多指标同时计算
- oracle
- 无法实时计算,只能预先约定查询要求,提前一天预计算
- 10并发共2000指标计算不到3秒
- 无需预先准备,临时选择任意标签组合,实时查询结果
案例某银行客户画像系统客群交集统计
- 数据量巨大,上亿客户,数千客群多对多关系,几十个维度
- 任选若干客群计算交集,中间结果集巨大,无法预计算
- 10个以上并发请求
- hadoop上著名olap server,100cpu 集群
- 单任务 2分钟
- 12cpu单任务4秒
- 10任务并发可在10秒内完成
某银行bi系统的前置数据库
中央数据仓库承担全行的数据任务,负担过重,只能分配给bi系统5个并发
仅对少量高频数据,db2也无法胜任实时查询,更无法实现数据路由,需要用户选择数据源
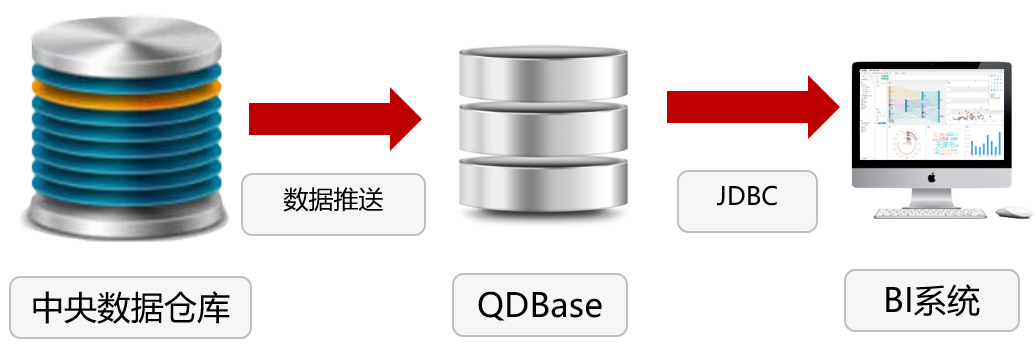
qdbase存储少量高频数据,大量低频数据仍存储在数据仓库中,避免重复建设
qdbase承担绝大多数的高频计算任务,剩下少量低频任务自动路由到中央数据仓库
某保险公司 - 库外存储过程
vertica不支持存储过程,要写异常复杂的嵌套sql准备数据,经常还要借助java代码
与mysql的混合计算时要先将mysql数据转入,繁琐、不实时、数据库臃肿

用户评价
the best use for us is to pass parameters to the vertica database.
each cell becomes a data array that are easy to use, compare and manipulate. it is very logical and you have made it user friendly.03qdbase凭什么?
sql为什么难写:一支股票最长连涨了多少天
select max(continuousdays)
from (select count(*) continuousdays
from (select sum(updowntag) over ( order by tradedate) norisingdays
from (select tradedate,
case when price>lag(price) over ( order by tradedate)
then 0 else 1 end updowntag
from stock ) )
group by norisingdays )
sql对有序运算支持不足,未直接提供有序分组,只能采用迂回思路,写成四层嵌套的形式
这样的句子不仅很难写出来,写出来想看懂也不容易
面对复杂的业务逻辑,sql的复杂度会陡增,既难懂又难写
这并非罕见需求,现实中数千行的sql代码中这种情况比比皆是,严重影响开发和维护效率
sql为什么跑不快:1亿条数据取前10名
select top 10 * from orders order by amount desc
这个查询用了order by,严格按此逻辑执行,意味要将全量数据做排序,性能将很差
我们知道有不必全排序而完成这个运算的办法,但用sql无法描述,只能寄希望于数据库的优化引擎
简单情况(比如本句),很多数据库都能优化,但情况再复杂一些,数据库优化引擎就会晕了
下面的分组内取前n名,sql无法直接描述了,还是要采用迂回思路利用窗口函数写成子查询
面对这种迂回写法,数据库优化引擎也不会优化了,只能去执行排序
select * from (
select *, row_number() over (partition by area order by amount desc) rn
from orders )
where rn<=10
spl的解决方法
| a | |
| 1 | =stock.sort(tradedate).group@i(price< price[-1]).max(~.len()) |
这句spl和前面sql的运算逻辑相同,但spl提供 有序分组运算,描述起来直观简洁
| a | ||
| 1 | =file(“orders.ctx”).open().cursor() | |
| 2 | =a1.groups(;top(10;-amount)) | 金额在前10名的订单 |
| 3 | =a1.groups(area;top(10;-amount)) | 每个地区金额在前10名的订单 |
spl将topn视为返回集合的聚合运算,避免全排序;全集和分组时写法类似,不再迂回
spl为什么更有优势
普通人这么算
- 1 2=3
- 3 3=6
- 6 4=10
- 10 5=15
- 15 6=21
- …
高斯这么算
- 1 100=101
- 2 99=101
- 3 98=101
- …
- 一共有50个101
- 50*101= 5050
使用了乘法 !
spl则相当于发明了乘法!简化书写,提高性能
spl基于完全不同的理论体系:离散数据集,提供更丰富的数据类型和基础运算,拥有更强大的表达能力
高性能计算理念
硬件 ?
算法 ✓
开发 ≠
数据库 ✗
玩爆sql的常见场景
1、复杂有序计算:用户行为转换漏斗分析
- 计算每个事件(页面浏览、搜索、加购物车、下单、付款等)后的用户流失率
- 多个事件在指定时间窗口内完成、按指定次序发生才有效,sql难以实现,更难优化
2、多步骤大数据量跑批
- 复杂业务需求难以直接用sql完成,游标读数计算慢,且难以并行,浪费计算资源
- 存储过程实现要几千行数十步,伴随中间结果反复落地,跑批时间窗口内完不成
3、大数据上多指标计算,反复用关联多
- 一次完成数百个指标的计算,多次使用明细数据,期间还涉及关联,sql需要反复遍历
- 大表关联、条件过滤、分组汇总、去重计数混合运算,伴随高并发实时计算
电商漏斗运算
with e1 as (
select uid,1 as step1,min(etime) as t1
from event
where etime>= to_date('2021-01-10') and etime < to_date('2021-01-25')
and eventtype='eventtype1' and …
group by 1),
e2 as (
select uid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from event as e2
inner join e1 on e2.uid = e1.uid
where e2.etime>= to_date('2021-01-10') and e2.etime < to_date('2021-01-25')
and e2.etime > t1 and e2.etime < t1 7
and eventtype='eventtype2' and …
group by 1),
e3 as (
select uid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from event as e3
inner join e2 on e3.uid = e2.uid
where e3.etime>= to_date('2021-01-10') and e3.etime < to_date('2021-01-25')
and e3.etime > t2 and e3.etime < t1 7
and eventtype='eventtype3' and …
group by 1)
select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from e1
left join e2 on e1.uid = e2.uid
left join e3 on e2.uid = e3.uid
sql缺乏有序计算且集合化不够彻底,需要迂回成多个子查询反复join的写法,编写理解困难而且运算性能非常低下
限于篇幅,只写了三步漏斗,再增加步骤时还要增加子查询
| a | |
| 1 | =["etype1","etype2","etype3"] |
| 2 | =file("event.ctx").open() |
| 3 | =a2.cursor(id,etime,etype;etime>=date("2021-01-10") && etime < date("2021-01-25") && a1.contain(etype) && …) |
| 4 | =a3.group(uid).(~.sort(etime)) |
| 5 | =a4.new(~.select@1(etype==a1(1)):first,~:all).select(first) |
| 6 | =a5.(a1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==a1.~ && etime>t && etime < t1 7).etime, null)))) |
| 7 | =a6.groups(;count(~(1)):step1,count(~(2)):step2,count(~(3)):step3) |
spl提供有序计算且集合化更彻底,直接按自然思维写出代码,简单且高效。
这段代码能够处理任意步骤数的漏斗,只要改变参数即可
spl部分高性能计算机制
java为什么也不行?
java过于原生,缺少必要数据类型和计算库,导致应用程序员写出难或写不出
calendar cal = calendar.getinstance();
map < object, doublesummarystatistics> c = orders.collect(collectors.groupingby(
r -> {
cal.settime(r.orderdate);
return cal.get(calendar.year) "_" r.sellerid;
},
collectors.summarizingdouble(r -> {
return r.amount;
})
)
);
for(object sellerid:c.keyset()){
doublesummarystatistics r =c.get(sellerid);
string year_sellerid[]=((string)sellerid).split("_");
system.out.println("group is (year):" year_sellerid[0] "\t (sellerid):" year_sellerid[1] "\t sum is:" r.getsum());
}
高性能算法难以实现
- 导致被迫使用好写的低性能算法,经常跑不过sql
没有通用的高性能存储
- 只能使用数据库或文本性能低
- 自己实现高性能存储又面临难以实现的困境
python为什么还不行?
python的dataframe并不擅长处理复杂情况下的结构化数据计算
import pandas as pd
import datetime
import numpy as np
import math
def salary_diff(g):max_age = g['birthday'].idxmin()min_age =
g['birthday'].idxmax()diff = g.loc[max_age]['salary']-
g.loc[min_age]['salary']return
diffemp['birthday']=pd.to_datetime(emp['birthday'])salary_diff=
emp.groupby('dept').apply(salary_diff)print(salary_diff)
运算完善度方面仍有不足
- 相邻引用、有序分组、定位计算、非等值分组等计算较繁琐
语法一致性差
- 一些相近计算会采用不同函数
大数据能力差
- 没有外存游标机制和并行能力
无通用高性能存储
- 与java一样没有高效存储
04技术特性
运行环境
- jdk1.8 及以上版本的 jvm 环境
- 任何操作系统,包括vm和container
- 空间占用不足1g,除第三方包外的核心包不足15m,可以运行在android上
- 资源消耗比数据库小;加大内存、增强cpu和硬盘会提升性能
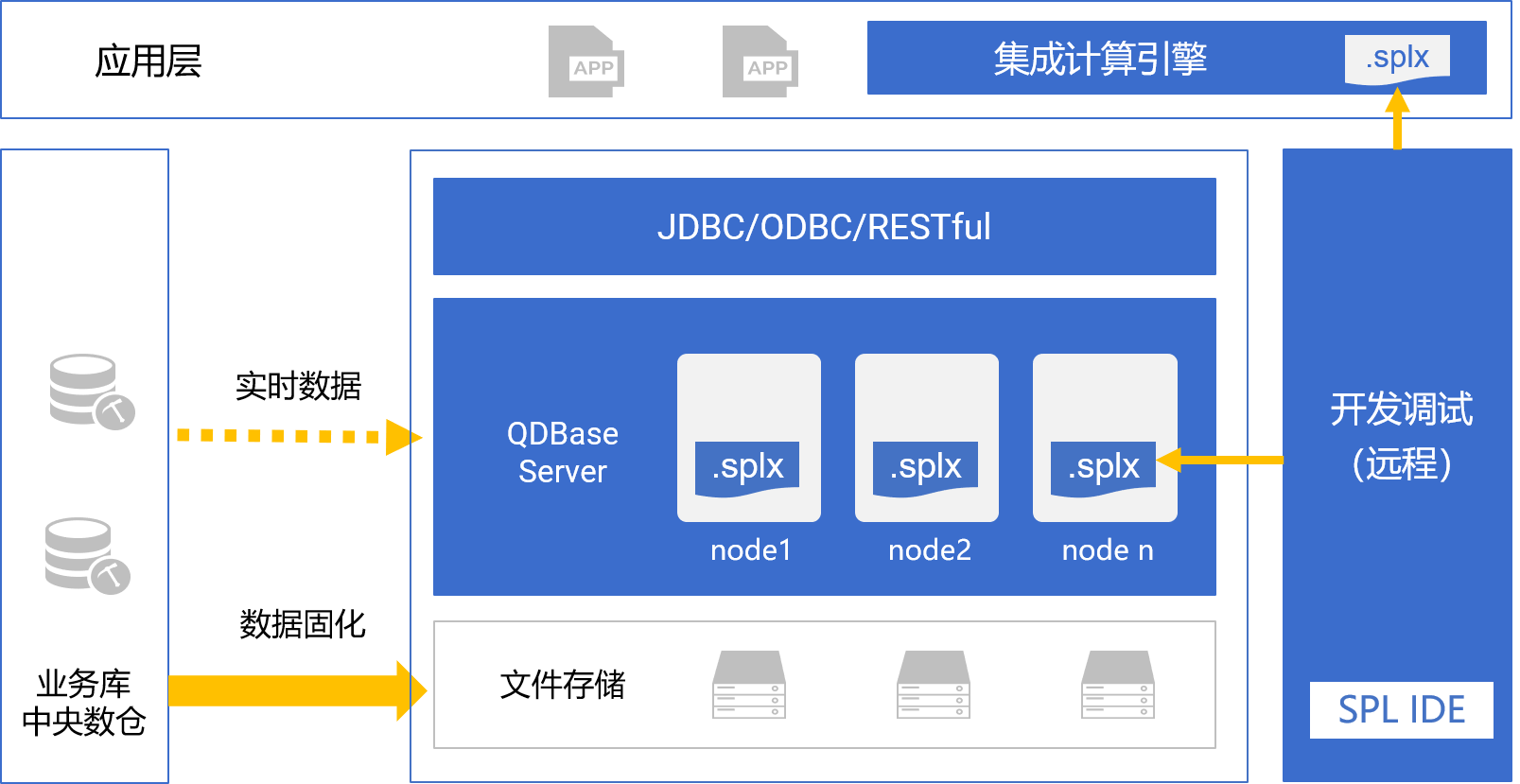
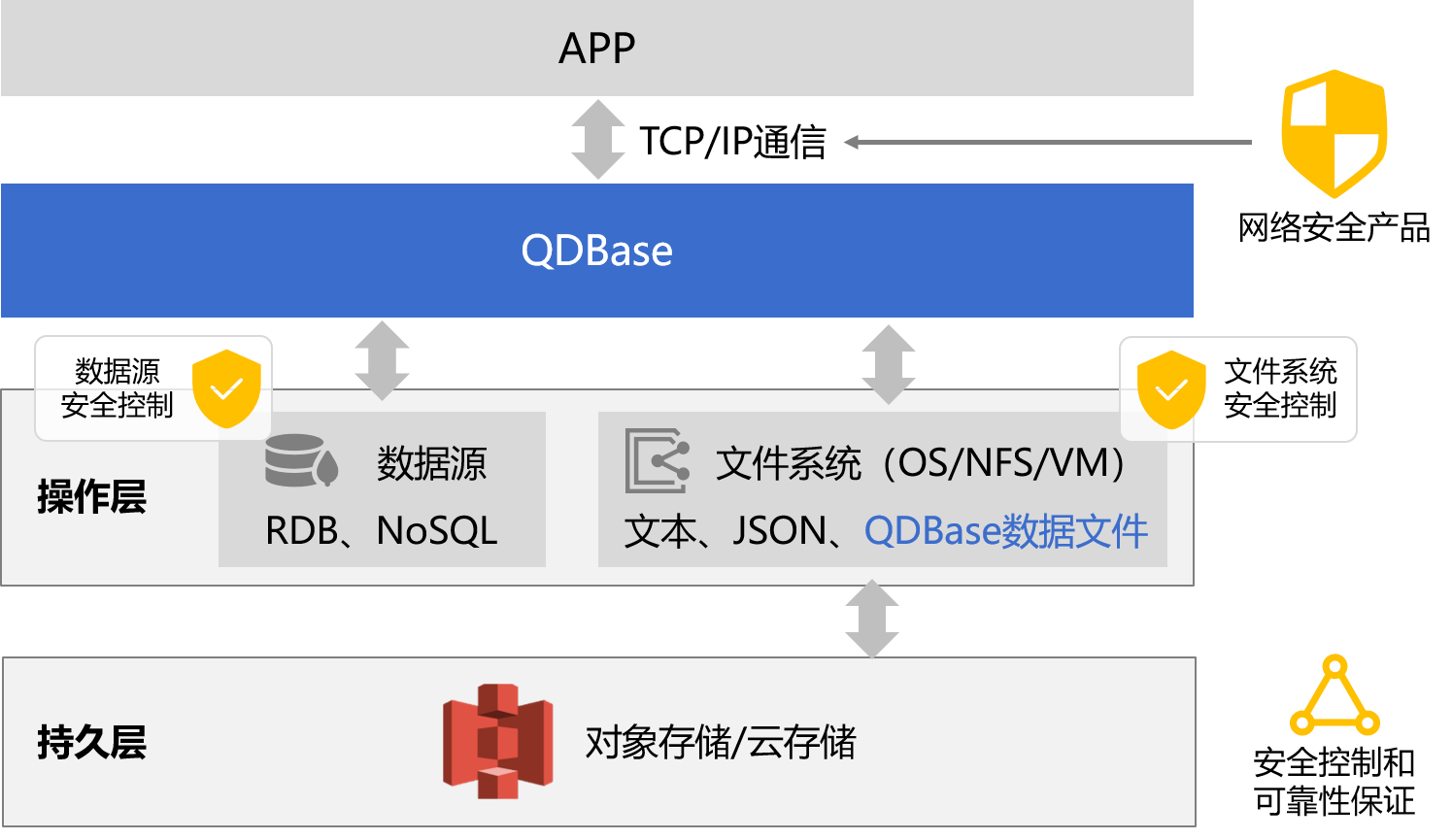
qdbase 技术架构
简洁易用的开发环境
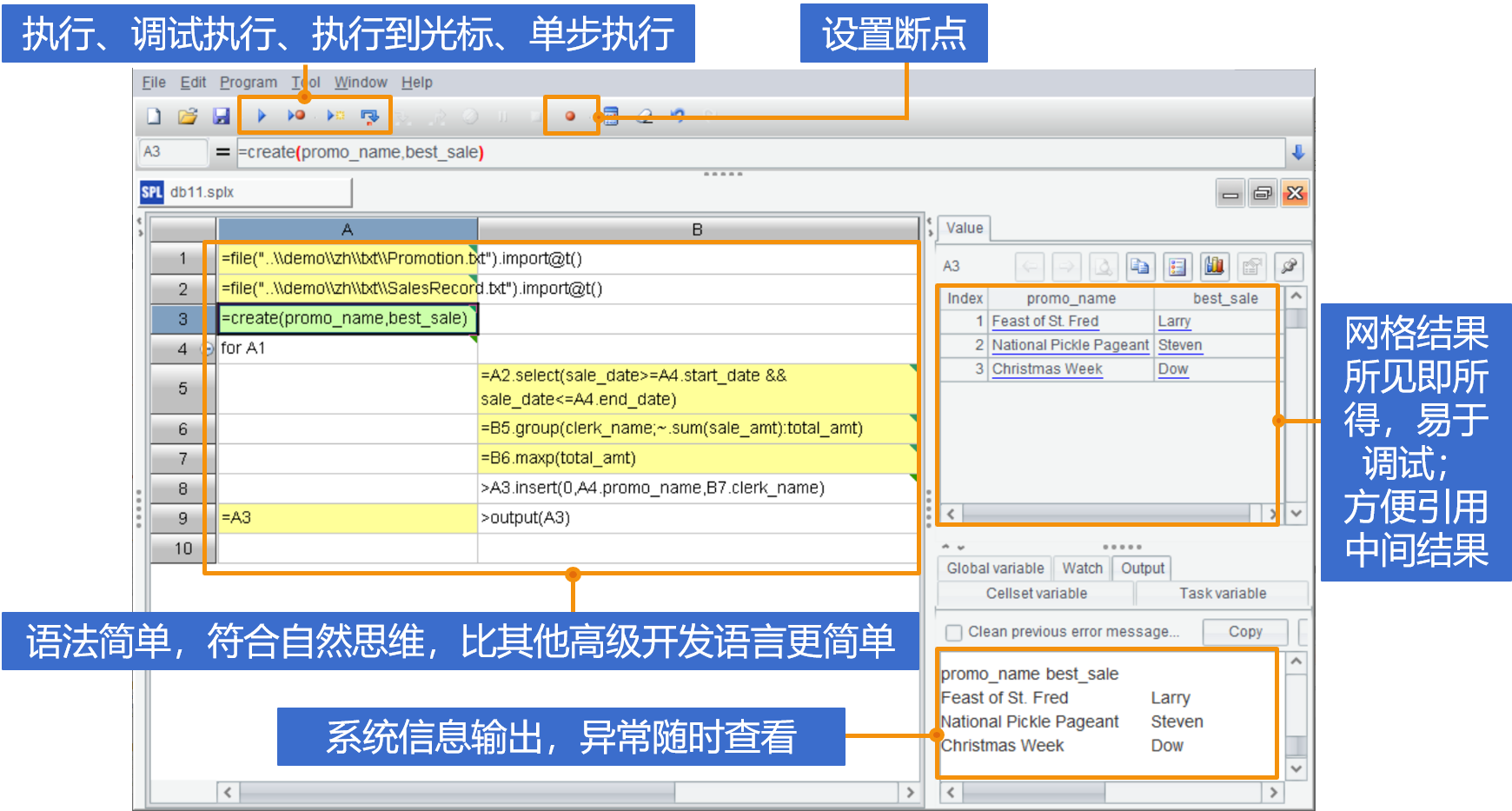
专门设计的语法体系
spl特别适合复杂过程运算
丰富的运算类库
专门针对结构化数据表设计
超强集成性
qdbase采用java开发,可独立运行,也可无缝集成到应用
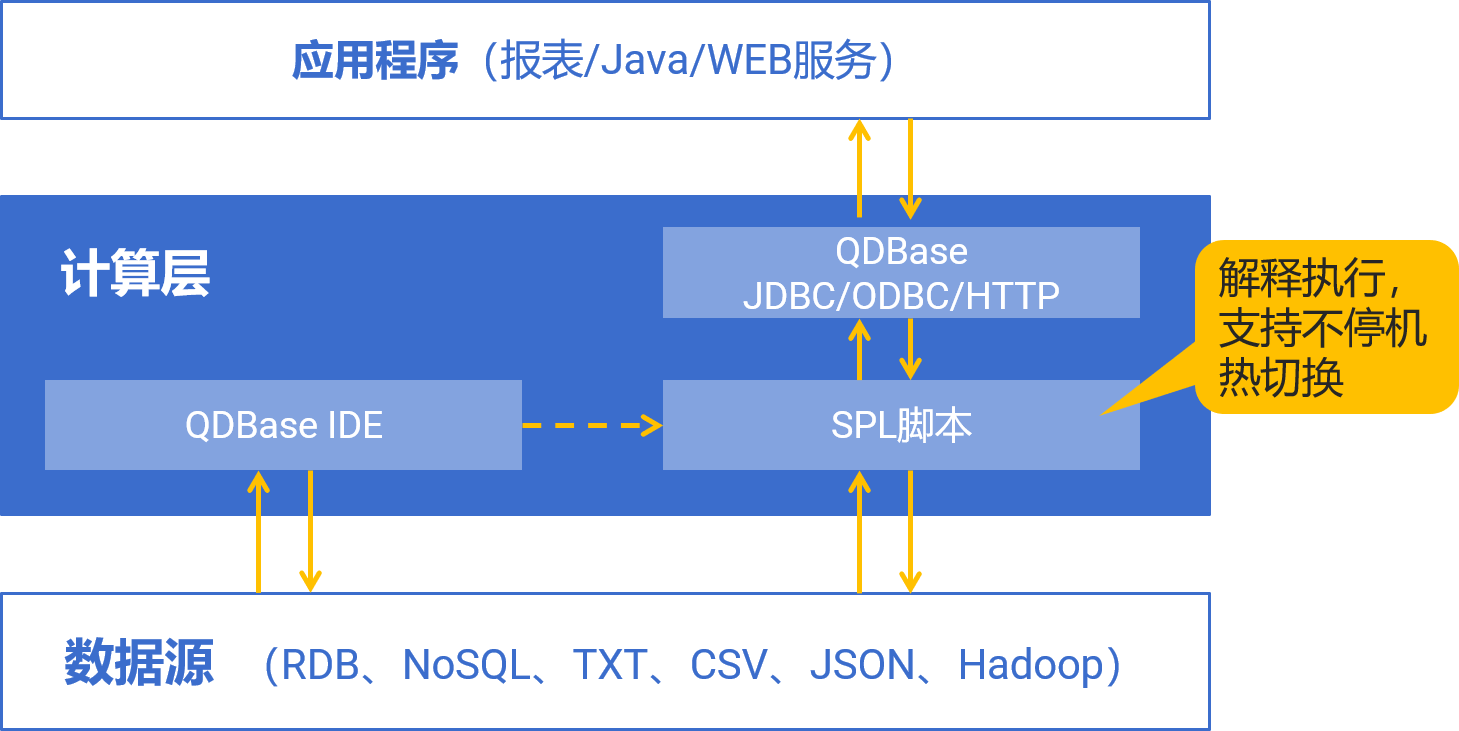
多样性数据源支持
直接使用多个数据源混合计算

可处理数据类型
- 结构化文本:txt/csv
- 普通文本,字串分析
- excel文件内数据
- 多层结构化文本:json, xml
- 结构化数据:关系数据库
- 多层结构化数据:bson
- kv型数据:nosql
灵活高效的文件存储
高性能
自有数据存储格式,集文件、组表
文件系统
可用树状目录方式按业务分类存储数据
集文件
- 倍增分段方式支持任意数量并行
- 自有高效压缩编码(减少空间;cpu占用少;安全)
- 泛型存储,允许集合数据
组表
- 行列混合存储
- 有序存储提高压缩率和定位性能
- 高效智能索引
- 倍增分段方式支持任意数量并行
- 主子表合一减少存储与关联
- 排号键值实现高效定位关联
数据存储与交换
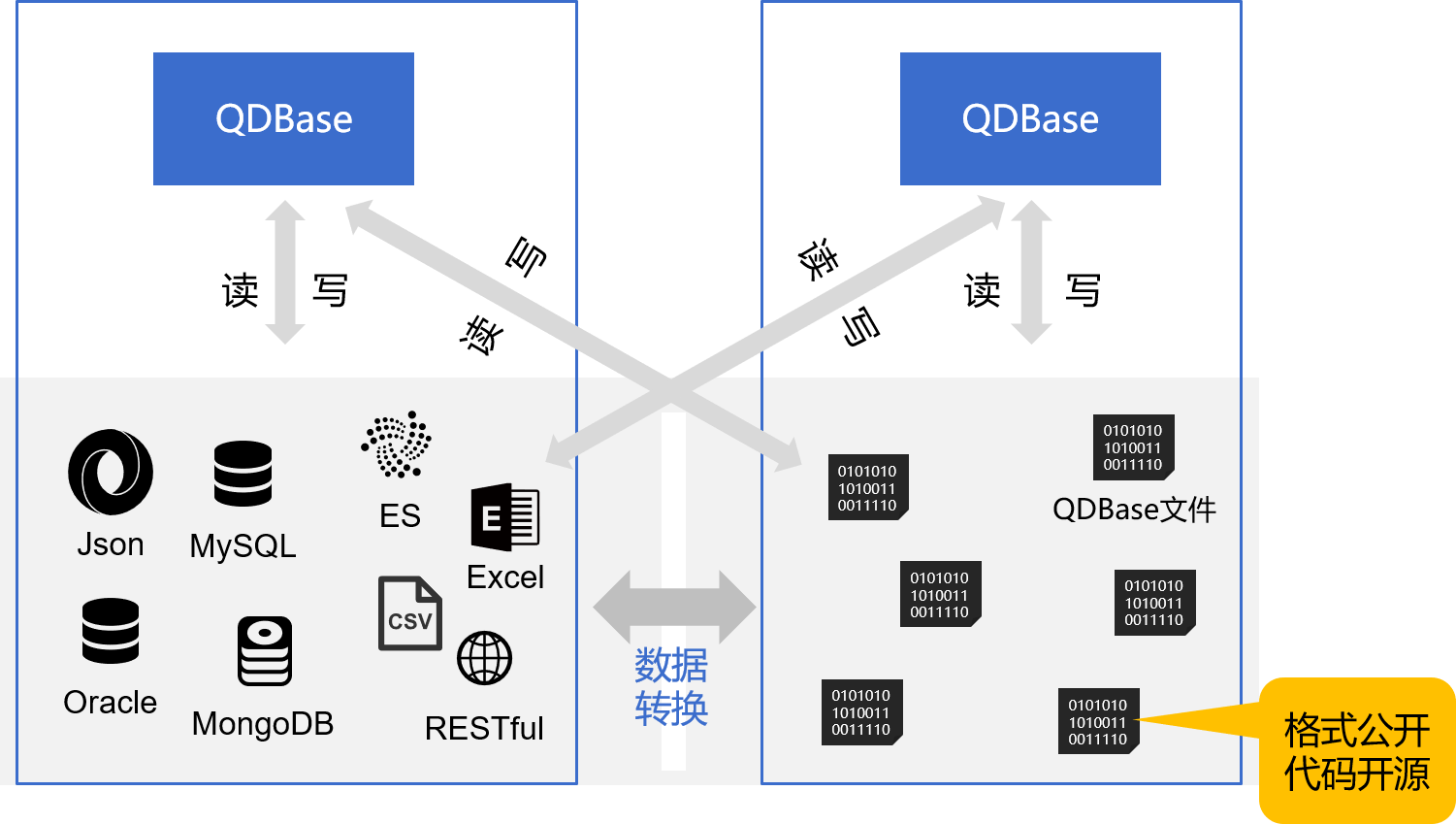
- qdbase不拥有数据,所有数据源的逻辑地位等同,能访问到的都是qdbase的数据
- 没有库内库外概念,没有入库出库动作,只有转换(可用spl实现)
数据安全和可靠
05更多方案
数据型微服务实现
问题
- 微服务等主流架构要求在应用端实施数据处理
- 数据库很难嵌入前端应用使用,只能硬编码
- java/orm缺乏结构化计算类库导致数据处理开发困难,无法热切换
九游会登陆的解决方案
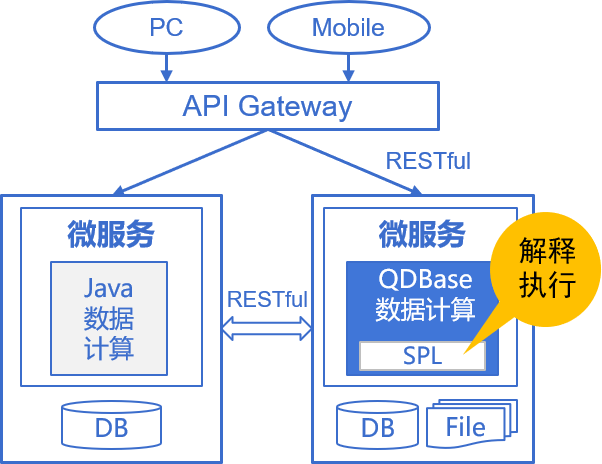
- spl替代java/orm在(微服务)应用内实施数据计算
- 丰富计算类库与敏捷语法简化开发
- 体系开放可以实时处理任意数据源数据
- spl解释执行,天然支持热切换
- 高效算法与并行机制保证计算性能
替代存储过程
问题
- 存储过程编辑调试困难,缺乏移植性
- 编译存储过程对权限要求过高,安全性差
- 存储过程被多个应用共用还会造成应用间紧耦合
九游会登陆的解决方案

- spl天然适合复杂多步数据计算
- spl脚本天然可移植
- 脚本只要求数据库的读权限,不会造成数据库安全问题
- 不同应用的脚本分别存储于不同目录,不会造成应用间耦合
消灭数据库中间表
问题
- 为了查询效率或简化开发会在数据库中生成大量中间表
- 中间表空间占用大,导致数据库过于冗余臃肿
- 不同应用使用同一个中间表会造成紧耦合,中间表管理困难(很难删除)
九游会登陆的解决方案

- 中间表存储在数据库中是为了利用数据库进行后续计算,使用文件存储后可使用spl实施后续计算
- 外置中间表(文件)更易于管理,采用不同目录存储不会引起应用耦合性问题
- 中间表外置可以为数据库充分减负,甚至不需要部署数据库
应对报表没完没了
问题
- 报表/bi工具只能解决呈现环节的问题,对数据准备无能为力
- 数据准备使用sql/存储过程/java硬编码,开发维护困难,成本高
- 报表需求客观上没完没了,数据准备是导致高开发成本的主要因素
九游会登陆的解决方案

- 在报表呈现和数据源之间增加计算层来解决数据准备问题
- spl简化报表数据准备,弥补报表工具计算能力不足,全面提升报表开发效率
- 报表呈现和数据准备两个环节都能快速响应以低成本应对没完没了的报表需求
可编程路由实现前置计算
数据仓库任务繁重,需要前置计算分担压力
- 仅高频数据前置,接管大部分计算请求
- 可编程路由能力自动选择前置库和数据仓库并混合计算结果,应用可透明访问全量数据
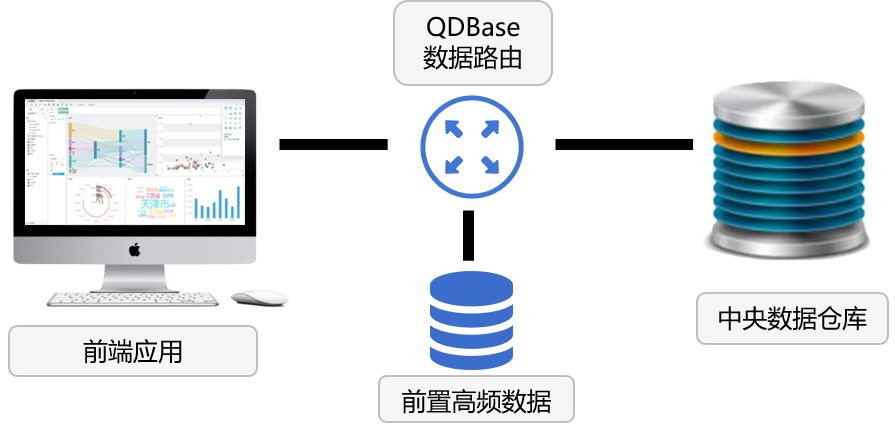
路由能力实现低成本高性能全量数据分析
传统数据库实现前置计算的尴尬
- 前端应用可能访问所有数据,全量数据前置造成重复建设,成本高
- 缺乏路由能力,仅部分数据前置时,应用不可透明访问全量数据,体验差
混合计算实现实时htap
冷热混算实现t 0实时分析
- 历史冷数据精心整理
- 交易热数据实时读取
生产系统无须改造
- 充分利用原有多样数据源优势

用开放的多源混算能力支撑低风险高性能强实时htap
htap数据库难以实现htap需求
- 要求更换生产系统数据库,风险大
- sql算力不足,历史数据准备不充分,性能低
- 计算能力封闭,外部多样性数据源要求复杂etl过程,实时差
文件计算实现湖仓一体
- 公开格式文件数据计算
- txt/csv/xls/json/xml
- 高性能私有格式文件存储与计算
- 随意进入,逐步整理;lake to house
- 丰富数据源接口,直接实时计算
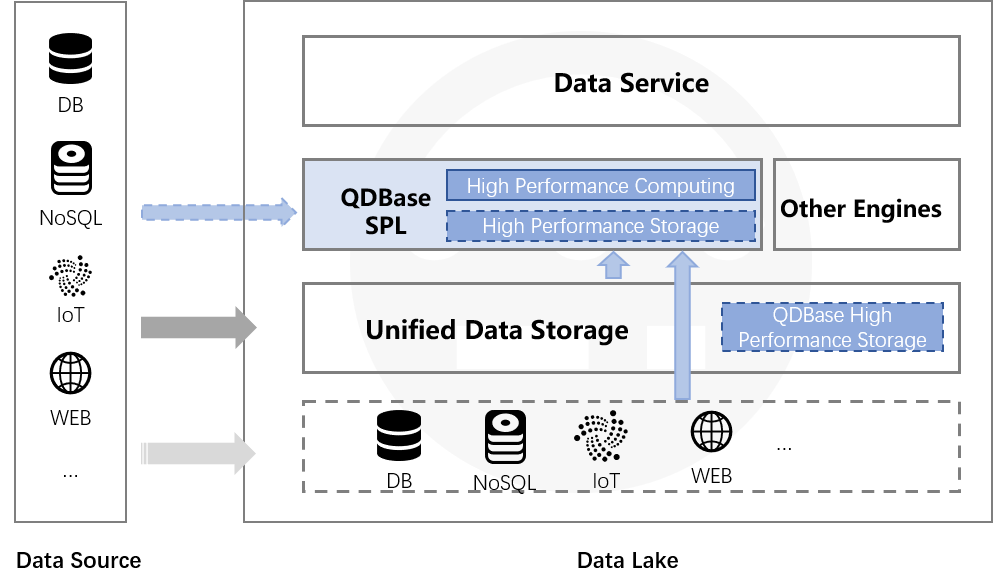
- rdb只能house不能lake
- 强约束,不合规的数据进不来,复杂etl过程低效
- 封闭性,外部数据无法计算,更不能混合实时计算
06常见问题
qdbase基于全新的计算模型,无开源技术可以引用,从理论到代码全部自主创新

基于创新理论的qdbase不能再使用sql实现高性能,sql无法描述大部分低复杂度算法
qdbase 完全用纯java开发,可以在任何有jvm的操作系统下运算,包括虚拟机、云服务器以及容器,甚至可以运行在android 上。
qdbase 提供了标准的jdbc驱动,可被java应用无缝集成调用。
对于非java应用,qdbase提供了http/restful调用接口。
作为拥有良好集成性的java产品,可以无缝与各种 java 框架和应用服务器集成使用,其逻辑地位与自写的java代码等同
对于计算型框架(比如 spark),虽然qdbase能被无缝集成,但并没有实际意义,qdbase可以替代spark计算
特别地,qdbase自有流式计算能力,不需要被流计算框架(比如 flink)集成,通常会更好的功能和性能
当然没问题!
不过,因为数据库i/o性能不佳, qdbase在这种情况下不能保证高性能, 而且数据库通常也不提供低复杂度算法需要的存储。要获得高性能,则需要qdbase自己存储数据
qdbase使用自有格式的文件来存储数据,任何操作系统下的文件系统都支持,包括网络文件系统。这样,qdbase可以天然地实现存算分离机制。
嵌入应用使用时,可靠性由应用保障
独立使用时,提供负载均衡和容错机制,但单任务可能失败,仅适合小规模集群
不提供故障后自动恢复功能
云版本的弹性计算机制在分配 vm 时会避开当前失效的节点,一定程度实现高可用
可使用提供的接口,调用 java 写的静态函数来扩展功能
qdbase也开放了自定义函数的接口,注册后即可在spl中使用
和rdb相比
qdbase的元数据能力相对不成熟,大部分计算要从访问数据源(文件)开始,对于简单运算会有些麻烦。
和hadoop/mpp相比
qdbase提供有集群能力,但缺乏机会历练。
历史上,qdbase多次用单机替代原有的集群,仍获得同样甚至更高的性能。
和python相比
spl 正在发展人工智能功能,但目前和python相差还比较远。
spl不是 sql 体系的计算引擎,目前仅支持小数据量下的简单sql且不保障性能。可以认为qdbase不支持sql,当然也不会和任何sql存储过程兼容。
未来会发展出支持 sql 的双引擎,但仍然很难保证高性能和大数据,仅仅是让存量的 sql 代码易于迁移
目前还没有。
sql语句的信息不足, 需要猜出其目标才能设计合理的优化路径。我们优化sql的经验远不如传统数据库厂商,这时候直接把sql转换成spl通常会导致更差的性能。
spl专门用于低代码和高性能
spl语法很容易,有java/sql基础者只要数小时即可入门,数周就能熟练
“难”,高性能算法有点难, 需要学习更多算法知识
“不难”,一旦学会,很多高性能任务都成为“套路”
最初的1-2个场景,由我方工程师介入配合用户实现
大多数程序员习惯了sql思维方式,不熟悉spl的思维方式,需要用一两个场景训练和理解
性能优化套路经历过也就学会了,算法设计和实现并不是那么难

授人以鱼不如授人以渔!
07优势总结
qdbase优势总结
性能卓越
大数据处理速度比传统方案平均提高1个数量级
高效开发
语法过程化,符合自然思维
丰富类库
灵活开放
多源混合计算
独立、嵌入多种应用方式
资源节省
单机顶集群,减少硬件开销
绿色环保
成本锐减
开发、硬件、运维成本降低x倍
